


In its debut on the MLPerf trade benchmarks, the NVIDIA GH200 Grace Hopper Superchip ran all knowledge heart inference exams, extending the main efficiency of NVIDIA H100 Tensor Core GPUs.
The general outcomes confirmed the distinctive efficiency and flexibility of the NVIDIA AI platform from the cloud to the community’s edge.
Individually, NVIDIA introduced inference software program that can give customers leaps in efficiency, vitality effectivity and complete price of possession.
GH200 Superchips Shine in MLPerf
The GH200 hyperlinks a Hopper GPU with a Grace CPU in a single superchip. The mixture gives extra reminiscence, bandwidth and the flexibility to routinely shift energy between the CPU and GPU to optimize efficiency.
Individually, NVIDIA HGX H100 programs that pack eight H100 GPUs delivered the best throughput on each MLPerf Inference take a look at on this spherical.
Grace Hopper Superchips and H100 GPUs led throughout all MLPerf’s knowledge heart exams, together with inference for pc imaginative and prescient, speech recognition and medical imaging, along with the extra demanding use instances of advice programs and the massive language fashions (LLMs) utilized in generative AI.
Total, the outcomes proceed NVIDIA’s document of demonstrating efficiency management in AI coaching and inference in each spherical because the launch of the MLPerf benchmarks in 2018.
The most recent MLPerf spherical included an up to date take a look at of advice programs, in addition to the primary inference benchmark on GPT-J, an LLM with six billion parameters, a tough measure of an AI mannequin’s measurement.
TensorRT-LLM Supercharges Inference
To chop by means of complicated workloads of each measurement, NVIDIA developed TensorRT-LLM, generative AI software program that optimizes inference. The open-source library — which was not prepared in time for August submission to MLPerf — allows clients to greater than double the inference efficiency of their already bought H100 GPUs at no added price.
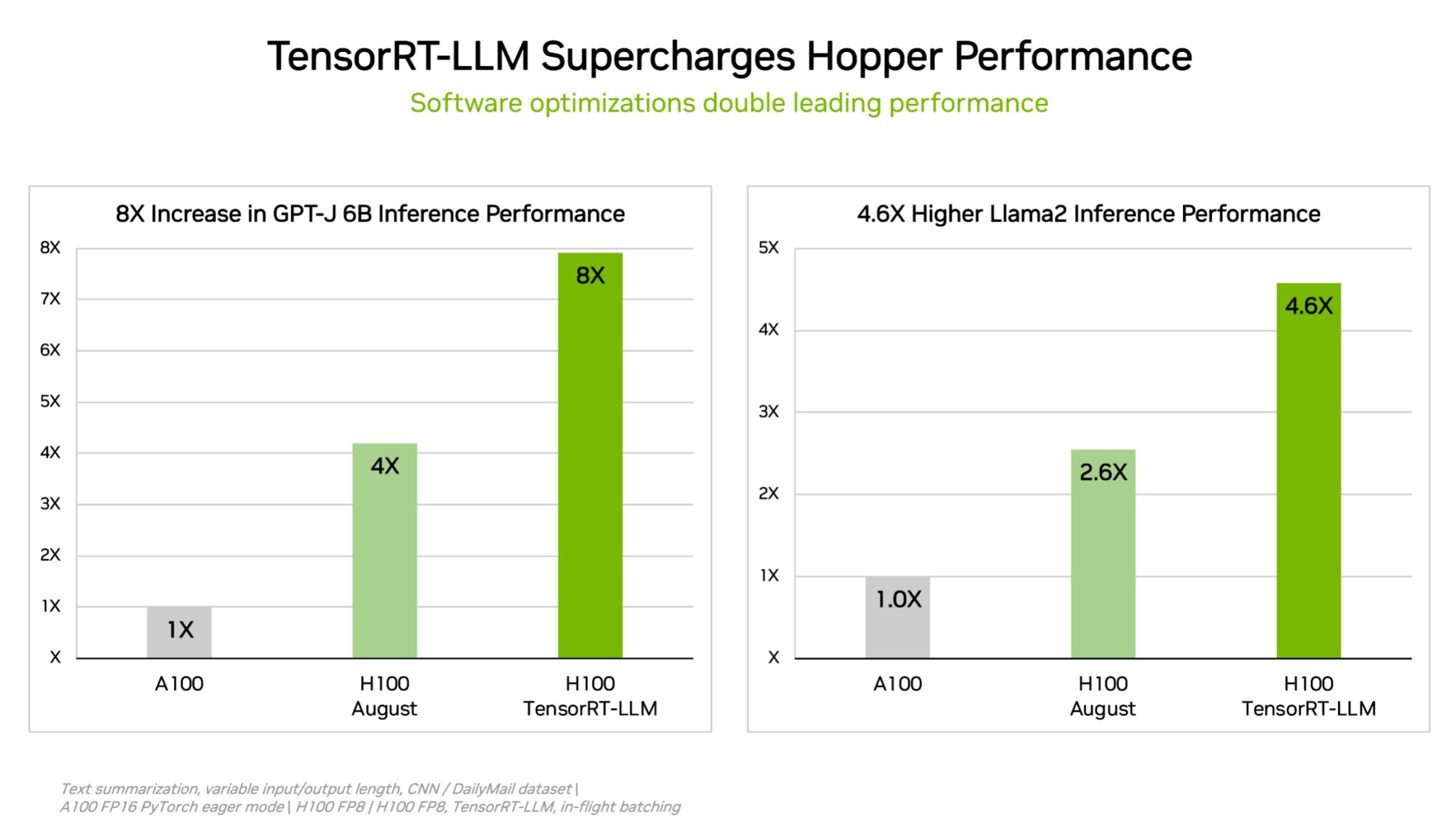
NVIDIA’s inner exams present that utilizing TensorRT-LLM on H100 GPUs gives as much as an 8x efficiency speedup in comparison with prior era GPUs operating GPT-J 6B with out the software program.
The software program obtained its begin in NVIDIA’s work accelerating and optimizing LLM inference with main firms together with Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (now a part of Databricks), OctoML, Tabnine and Collectively AI.
MosaicML added options that it wants on prime of TensorRT-LLM and built-in them into its current serving stack. “It’s been an absolute breeze,” stated Naveen Rao, vice chairman of engineering at Databricks.
“TensorRT-LLM is easy-to-use, feature-packed and environment friendly,” Rao stated. “It delivers state-of-the-art efficiency for LLM serving utilizing NVIDIA GPUs and permits us to cross on the associated fee financial savings to our clients.”
TensorRT-LLM is the newest instance of steady innovation on NVIDIA’s full-stack AI platform. These ongoing software program advances give customers efficiency that grows over time at no further price and is flexible throughout various AI workloads.
L4 Boosts Inference on Mainstream Servers
Within the newest MLPerf benchmarks, NVIDIA L4 GPUs ran the total vary of workloads and delivered nice efficiency throughout the board.
For instance, L4 GPUs operating in compact, 72W PCIe accelerators delivered as much as 6x extra efficiency than CPUs rated for almost 5x increased energy consumption.
As well as, L4 GPUs characteristic devoted media engines that, together with CUDA software program, present as much as 120x speedups for pc imaginative and prescient in NVIDIA’s exams.
L4 GPUs can be found from Google Cloud and plenty of system builders, serving clients in industries from shopper web providers to drug discovery.
Efficiency Boosts on the Edge
Individually, NVIDIA utilized a brand new mannequin compression expertise to reveal as much as a 4.7x efficiency enhance operating the BERT LLM on an L4 GPU. The consequence was in MLPerf’s so-called “open division,” a class for showcasing new capabilities.
The method is anticipated to search out use throughout all AI workloads. It may be particularly precious when operating fashions on edge units constrained by measurement and energy consumption.
In one other instance of management in edge computing, the NVIDIA Jetson Orin system-on-module confirmed efficiency will increase of as much as 84% in comparison with the prior spherical in object detection, a pc imaginative and prescient use case frequent in edge AI and robotics situations.
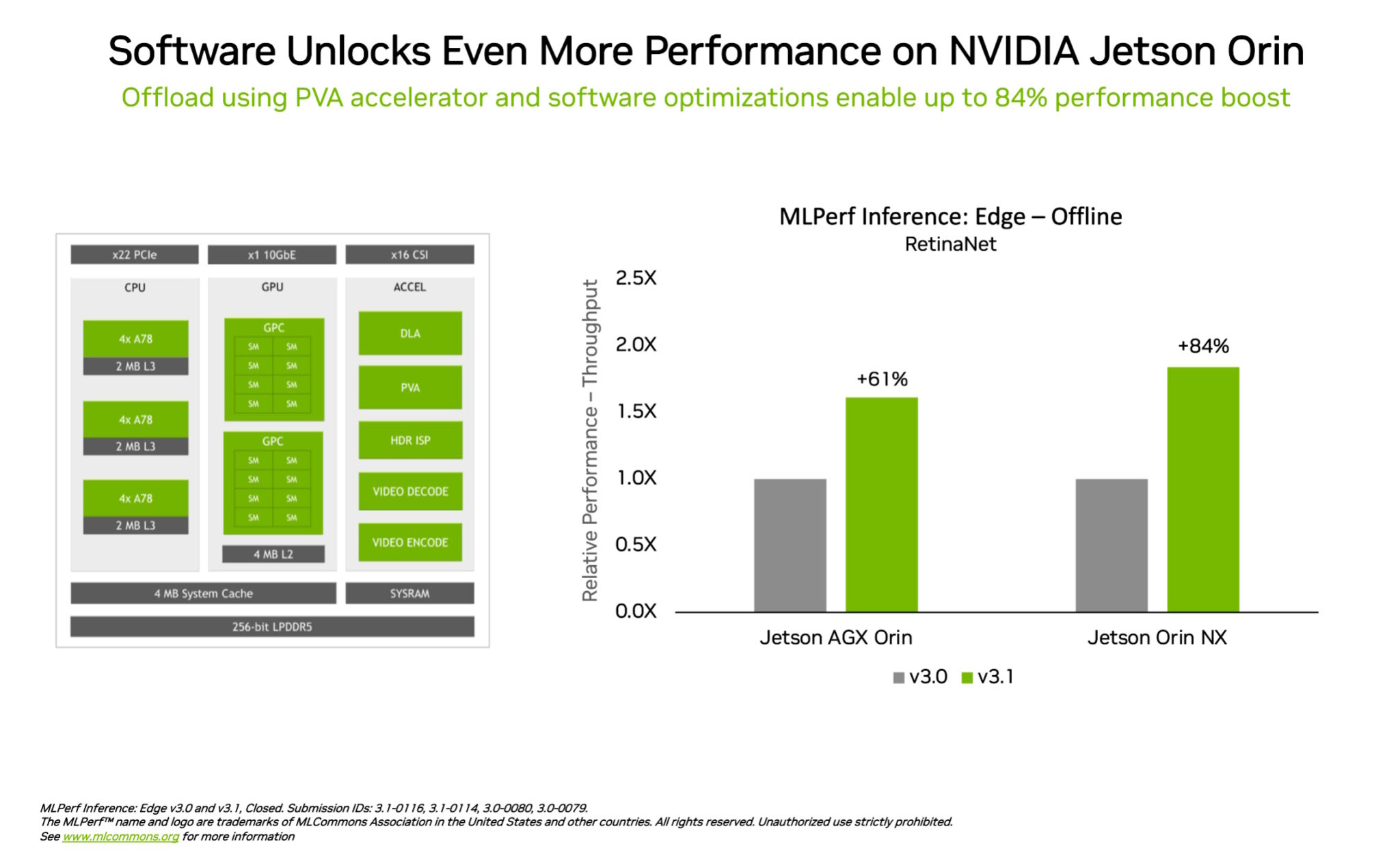
The Jetson Orin advance got here from software program profiting from the newest model of the chip’s cores, similar to a programmable imaginative and prescient accelerator, an NVIDIA Ampere structure GPU and a devoted deep studying accelerator.
Versatile Efficiency, Broad Ecosystem
The MLPerf benchmarks are clear and goal, so customers can depend on their outcomes to make knowledgeable shopping for choices. In addition they cowl a variety of use instances and situations, so customers know they will get efficiency that’s each reliable and versatile to deploy.
Companions submitting on this spherical included cloud service suppliers Microsoft Azure and Oracle Cloud Infrastructure and system producers ASUS, Join Tech, Dell Applied sciences, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, QCT and Supermicro.
Total, MLPerf is backed by greater than 70 organizations, together with Alibaba, Arm, Cisco, Google, Harvard College, Intel, Meta, Microsoft and the College of Toronto.
Learn a technical weblog for extra particulars on how NVIDIA achieved the newest outcomes.
All of the software program utilized in NVIDIA’s benchmarks is on the market from the MLPerf repository, so everybody can get the identical world-class outcomes. The optimizations are repeatedly folded into containers accessible on the NVIDIA NGC software program hub for GPU functions.